
马年农历春节前夜,国产智算卡再度迎来好音书!单卡FP8算力终于冲上1000TFLOPS了。
固然国产GPU厂商摩尔线程在两年前就推出了有益面向大模子覆按、推理及高性能研究设想的全功能GPU智算卡MTT S5000,可是具体的架构、参数和性能一直并未对外公布。
近日,摩尔线程首度公开了其旗舰居品S5000的详备参数:基于“平湖”架构,单卡FP8算力糟蹋1000T,集成80GB显存,1.6TB/s带宽,FP8到FP64全精度笼罩,覆按精度紧咬H100,差距不到1%!

这不仅是国产GPU初次在单卡隐约量上摸到海外顶尖门槛,更是为万亿参数大模子提供了真确可用的自主算力底座。
一、 中枢参数对标:1000TFLOPS与全精度笼罩
{jz:field.toptypename/}MTT S5000在设想之初便定位于“训推一体”的全功能基座,其硬件参数展现了极强的竞争上风:
●算力峰值: S5000单卡AI算力(FP8)最高可达 1000TFLOPS(即1 PFLOPS)。这一数据记号着国产GPU在单卡隐约量上已可与海外主流一较上下。
●研究精度: 该卡兑现了从 FP8、BF16、FP16到FP32、FP64 的全精度研究支捏。业内实测知道,S5000在居品研究精度上已超过英伟达H100,并在高精度研究材干上直追其最新的Blackwell架构。
●存储规格: 设立 80GB显存,显存带宽达 1.6TB/s。这一见地确保了在责罚超大鸿沟参数模子(如DeepSeek-V3)时,数据读取不会成为瓶颈。
●互联带宽: 卡间互联带宽达到 784GB/s,支捏万卡鸿沟的高效协同,极大擢升了区别式覆按的效果。
二、 架构上风:第四代MUSA与原生FP8引擎
S5000参数发扬稀奇的背后,是摩尔线程自主研发的 第四代MUSA架构“平湖”。
算作国内首批原生支捏 FP8精度 的覆按GPU,S5000内置了硬件级FP8 Tensor Core加快单位。比拟传统的BF16/FP16,FP8能将数据位宽减半,使显存带宽压力镌汰50%,表面研究隐约量径直翻倍。实测阐明,在DeepSeek、Qwen等前沿模子架构下,S5000的FP8引擎可擢升 30%以上的覆按性能。
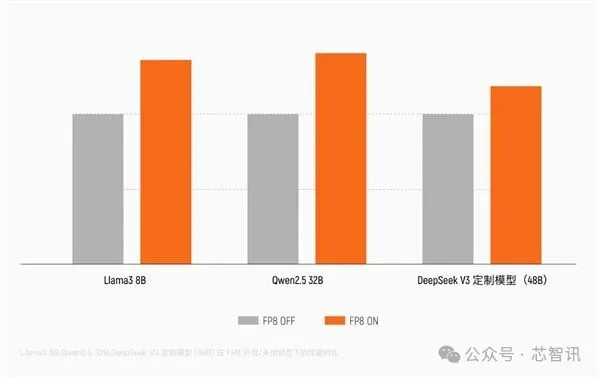
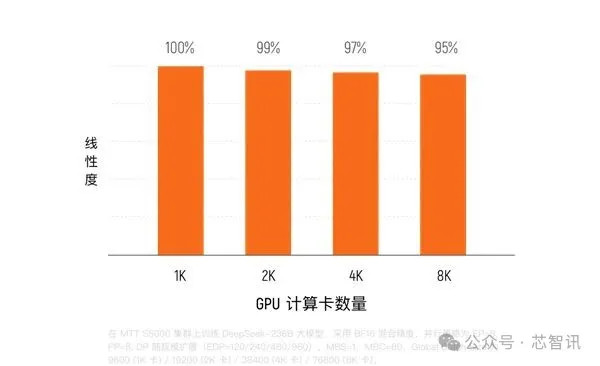
此外,S5000搭载了独创的 ACE(异步研究引擎)工夫。该工夫能将复杂的通讯任务从研究中枢中卸载,开云中国app登录入口兑现研究与通讯的零冲突并行。实测知道,从64卡扩张至1024卡,系统长久保捏90%以上的线性扩张效果,确保了算力参数能充分出动为实战性能。
三、 性能实测:高精度覆按对标H100
在典型任求实测中,S5000的参数上风出动成为权臣的效果:
●对比H20:在互联网厂商的端到端任务测试中,S5000的概述性能发扬约为英伟达H20的 2.5倍。
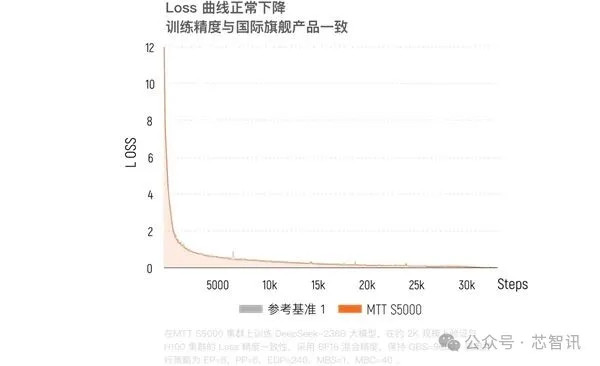
●对比H100: 智源讨论院基于S5000千卡集群覆按具身大脑模子RoboBrain 2.5,其覆按亏损值(loss)与H100集群的各异仅为 0.62%,重要见地瑕疵在千分之几,兑现了对顶尖算力的高度对都。
值得一提的是,S5000在推理场景相似发扬优异。比如在2025年12月,摩尔线程辘集硅基流动基于MTT S5000完成了对DeepSeek-V3 671B满血版的深度适配与性能测试。

实测S5000单卡Prefill隐约越过4000 tokens/s,Decode隐约越过1000 tokens/s,刷新了国产GPU的推理记录。
四、 生态落地:智谱GLM-5的Day-0适配考据
参数的遍及最终体当今对顶尖模子的支捏材干上。近日,在智谱风雅发布大模子 GLM-5 确今日,摩尔线程通告MTT S5000已圆满完成对该模子的 Day-0全经由适配与考据。
依托MUSA全栈软件平台对SGLang、PyTorch、vLLM等主流框架的原生适配,S5000不仅能兑现CUDA生态代码的“零资本”迁徙,更凭借其80GB显存和1.6TB/s带宽的参数底蕴,为GLM-5等万亿参数模子的快速迭代提供了坚实的国产算力支捏。
值得介意的是,固然S5000是2024年就已推出的居品,但其遴荐在2026年头初次公开详备性能参数,这一时机颇耐东说念主寻味——是否恰是摩尔线程为新一代“花港”架构的S6000系列预热的前奏?算作2025年12月发布的全功能GPU新架构,“花港”不仅支捏FP4到FP64的全精度研究,更兑现了研究密度擢升50%、能效比跃升10倍的糟蹋。基于新架构,专攻AI训推的“华山”与高性能渲染的“庐山”芯片是否已蓄势待发?S5000的不俗发扬,加上“花港”架构所展现的工夫纵深,已为国产算力的捏续进化掀开更多思象空间。
 备案号:
备案号: